
A reader recently asked if I had any documentation that would help to explain bit manipulation in MCP Extended Algol. I didn't, but this is an important subject in Algol programming, and it sounded like a good topic for a blog post. It also seemed like an opportunity to slip a little variety into the death march of MCP Express posts we all have been enduring for the past several months, so I'm interrupting our regularly-scheduled programming for this important topic.
A more general term for bit manipulation in Algol is partial-word operations, because Algol allows you to manipulate not just individual bits, but fields of contiguous bits within a word, i.e., parts of words or partial words. This feature of Algol is directly supported by operators in the MCP's E-mode architecture, so it is both safe and very efficient to use. There are a few subtleties you need to watch out for, however, which I'll point out as we go.
Bit field operations on most computer systems typically are carried out with a combination of shift/rotate operators and Boolean masking operators (AND, OR, etc). Algol and E-mode support full-word masking operations, but the E-mode architecture is unusual in that it does not have shift operators per se. It has something much better -- field isolation and field insertion operators. These can be used to implement many forms of shift and rotate, but they are better in that they can accomplish in one instruction what you normally need a combination of shift-and-mask operations to do on other systems.
Bit manipulation as we know it in Algol today got its start with the Burroughs B5000/B5500 systems, starting in the early 1960s. The notation used in Extended Algol for those systems was similar to that used in modern MCP Algol, as will be described below, but was more restricted -- bit numbers and field lengths had to be integer constants, the high-order bit in the word could not be accessed, and field lengths were limited to 39 bits in some cases. The bits were also numbered in the opposite order we use today.
Manipulating partial words at the instruction level actually started with a predecessor to the B5000, the Burroughs 220 (ca. 1958), a decimal, vacuum-tube, core memory system. The word on this system consisted of eleven BCD digits, with the high-order digit representing the sign. The digits were numbered in a word as "±1234567890", where ± represents the sign digit. The 220 (not the B220) had several instructions that would operate on a sequence of digits within a word. For example, an Increase Field Location instruction (IFL, op code 26) might be written:
IFL ADDR,62,13meaning add 13 to the word at the memory location represented by the symbol ADDR, but only to the "62" field, i.e., starting with digit #6 and extending two digits to the left. Thus, if the word at ADDR was originally -9999999999, after execution of this instruction it would be -9999129999. In this case the processor's overflow indicator would also have been set due to field overflow, but note that the carry did not propagate outside of digits 5 and 6, and none of the other digits in the word are altered. This idea of modifying a range of bits or digits within a word but leaving the rest of the word unaffected is central to the concept of partial-word operations.
Algol Word Formats
Since we will be talking about partial words, it will be useful to make clear up front what an Algol word is, how the word is formatted, and how the bits and partial-word fields are identified.
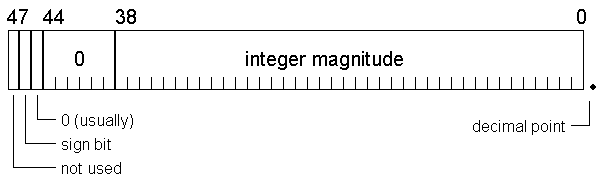
A word on modern E-mode systems physically occupies 64 bits, consisting of a 48-bit data portion, a four-bit tag that identifies control words, and an extension field. The tag and extension are used by the instruction set and the MCP, with only the data portion accessible directly by user programs. The bits in the data portion are numbered from 47 on the left (high-order) end to 0 on the right (low-order) end:

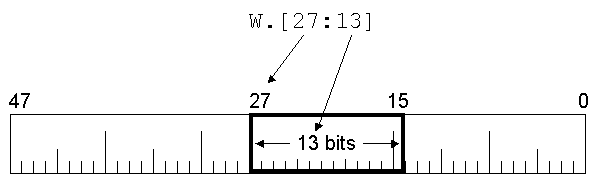
A partial word is identified by the notation [sb:nb], where:
- sb is the number of the starting, or high-order bit of the field
- nb is the number of bits in the field, extending to the right of the starting bit.
In Extended Algol, the period (".") is used as an operator to select a partial-word field from an expression value. This syntax is termed a partial-word designator:
W.[27:13]where W is an arithmetic expression (of type INTEGER, REAL, ALPHA, or DOUBLE) or a BOOLEAN expression. Graphically, the field in the word is positioned as shown below, occupying bits 27 through 15, inclusive:
When working with partial-word fields, you need to be aware of the internal layout of words used by the E-mode instruction set. E-mode differs from most architectures in that it does not have separate formats for integer and real (floating point) values. Instead, it has what is referred to as a unified numeric format. In this scheme, all arithmetic values are essentially floating point. Integers are simply floating-point values that have a binary fraction of zero, and that may be normalized in a specific fashion. The format of a single-precision floating-point word is this:

The fields in this word are used by the arithmetic operators as follows:
- [47:1] is ignored in arithmetic operations. E-mode uses the same arithmetic word format as the B5000/B5500. On those older systems, this was the "flag bit," which identified control words. That function is now performed by the tag field, which is not shown on these diagrams.
- [46:1] is the mantissa sign bit, 0=positive, 1=negative.
- [45:1] is the exponent sign bit, 0=positive, 1=negative.
- [44:6] is the exponent as a power of eight. Its representation is signed-magnitude.
- [38:39] is the mantissa or significand of the value, also represented as signed-magnitude.
The numeric value of the word can thus be understood as:
(Mantissa) × 8**(Exponent)
This format is unusual in its use of signed-magnitude instead of twos-complement values for the exponent and mantissa, the use of the exponent as a power of eight, and most particularly, that the scaling point is at the low-order end of the mantissa rather than at the high-order end as in most other systems. Because the exponent is a power of eight, the mantissa shifts in groups of three bits (termed "octades") during scaling and normalization. In arithmetic operations, the mantissa is neither required nor guaranteed to be normalized in any specific fashion, except for the case of integer operands discussed next.
Integers are normally represented as floating-point values with an exponent of zero. This implies that the mantissa will be normalized all the way to the right in the word. Typically the exponent sign in [45:1] will be zero for normalized integers, but that sign is irrelevant when the exponent is zero. A value fully normalized as an integer appears thus:
Note, however, that most integral values can have more than one representation. For example, the integer 123 (7B hex or 173 octal) has 11 representations, each representing a degree to which the mantissa is normalized. Here are three of those representations in hexadecimal:
00000000007B 2280003D8000 251EC0000000
Since the representation is based on octades, these are easier to appreciate in their respective octal forms:
0000000000000173 1050000017300000 1121730000000000
Note how the first nine bits (containing the exponent and its sign) change as the mantissa shifts within the word. In terms of their numeric value, these three representations (along with the eight others) are all identical, but of course the bit patterns are entirely different.
This representation of floating and integer values was specifically chosen to support the mixed-mode arithmetic requirements of Algol at the hardware level. There is only one set of arithmetic operators, not one for integers and one for floating point. The operators are implemented in such a way that, if both operands are normalized as integers and the result does not overflow the integer capacity, the result will be normalized as an integer as well. Note, however, that the Algol divide operator ("/") always produces a floating result, even if both operands are integers, and the MOD operator may produce a floating result.
There are operators in the E-mode instruction set that will normalize a value to integer representation if possible -- and throw an Integer Overflow fault if not. The Algol compiler automatically emits one of these operators before storing a value into an integer variable. The operators are available to Algol programmers as the INTEGER, INTEGERT, and ENTIER intrinsics. They vary in the type of normalization and rounding that they do, as described in Section 6 (Intrinsic Functions) of the Algol Programming Reference Manual.
The point of this long exposition on integer vs floating-point representation is that the distinction is especially important in partial-word operations. The partial-word operators treat a word as a bit vector and ignore its numeric layout. While you can be confident of the normalization of bits in a value read directly from an integer variable or returned by one of the normalization intrinsics, you should be less so of a value that is the result of a general arithmetic expression, regardless whether the operands are integer, floating-point or a combination thereof. Inserting values into partial-word fields for a integer variable can be especially problematic -- if the modified field intersects with the exponent field, then at best integer normalization may shift the mantissa bits at the time the value is assigned to the variable, and at worst the normalization may generate an Integer Overflow fault.
For this reason, partial-word operations are usually best done using arithmetic variables of type REAL rather than INTEGER The use of a REAL variable will avoid corrupting the result due to integer normalization at the time it is assigned to the variable.
Algol type DOUBLE values consist of two adjacent words. The first word has the same format as a single-precision floating-point (REAL) value. The second word contains an additional 39 low-order bits of mantissa and nine high-order bits of exponent. The decimal point remains to the right of the first word. See Appendix C in the Algol manual for details. It is important to note that partial-word operations on double-precision values affect only bits in the first word.
Algol type BOOLEAN values are represented as a 48-bit vector. Boolean masking operators (AND, OR, NOT, etc.) operate on all 48 bits in parallel. The "truthiness" of the value is determined solely by the low-order ([0:1]) bit in the word -- 0 is false and 1 is true. Since masking and partial-word operations are often used together, you should be familiar with the truth table for all of the Boolean operators:
| A | B | NOT A | A AND B | A OR B | A IMP B | A EQV B |
|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 0 | 0 | 1 | 1 |
| 0 | 1 | 1 | 0 | 1 | 1 | 0 |
| 1 | 0 | 0 | 0 | 1 | 0 | 0 |
| 1 | 1 | 0 | 1 | 1 | 1 | 1 |
IMP (implication) and EQV (equivalence) are included in the E-mode instruction set due to their specification in the Algol 60 report. Note that E-mode does not implement XOR (exclusive-OR), but EQV produces the ones-complement of XOR. Thus, if you need to compute the exclusive-OR of two bit masks, you can use NOT(A EQV B).
Field Isolation
Field isolation is perhaps the most common partial-word operation in Algol. It extracts a bit field from an arithmetic expression, right-justifies the field in a 48-bit word, clears the other bits in the word to zero, and returns that value. It is a shift-and-mask operation done in one step. Graphically, it works like this:
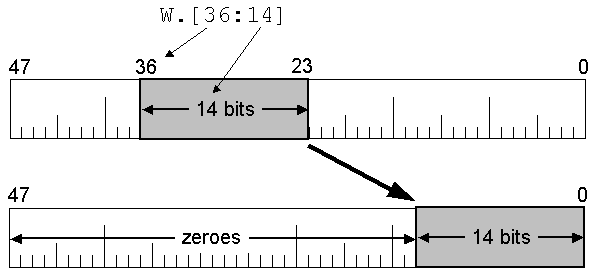
The starting bit number and field length can be any arithmetic expression -- both values will be rounded to integers as necessary. The starting bit number must be in the range 0-47. The field length must be in the range 0-48. If either restriction is violated, the system will throw an Invalid Operator fault. A field length of zero is not very useful, but is tolerated if it is specified as an arithmetic expression that must be evaluated at run time. The result of isolating a zero-length field is zero. If a zero length is specified as a literal, however, the compiler will flag it as an error.
Field isolation is a form of arithmetic or Boolean expression. The resulting value can be assigned to a variable or used as a primary in an enclosing expression, e.g.,
X:= W.[36:14] + 2;
X:= W.[36:14] - W.[47:8]*3;If the expression from which the field is being isolated is double-precision, the field is isolated from the first word of the double, the second word is discarded, and the operation returns a single-precision result.
When used with Boolean values, the field will be isolated as above. The "truthiness" of the result will be determined by bit [0:1] of the resulting value. Therefore, when testing whether a single bit is either zero or one, you do not need to compare the field to zero or one -- the partial-word expression can instead be tested directly, e.g.,
IF B.[33:1] THEN ...If you wish to test a single bit in an arithmetic expression, you can use the BOOLEAN type-transfer intrinsic to cast the value to Boolean -- this cast simply satisfies the compiler's type checking and generates no code, so it is a zero-cost conversion:
IF BOOLEAN(R.[33:1]) THEN ...Note that the field can be isolated either from the intrinsic's argument or from its result. This form is equivalent to the one above:
IF BOOLEAN(R).[33:1] THEN ...Similarly, small integer fields are often packed inside Boolean function result values, e.g., the STATE file attribute value returned by Algol READ and WRITE statements. You can extract these using the REAL type-transfer intrinsic -- another zero-cost conversion when the argument is a Boolean value:
BOOLEAN IORESULT;
INTEGER RECLENGTH;
IORESULT:= READ(INFILE, 15, BUF);
RECLENGTH:= REAL(IORESULT.[47:20]);See the File Attributes Programming Reference Manual for details on the format of fields within the STATE attribute value. The last statement above could have been written equivalently as:
RECLENGTH:= REAL(IORESULT).[47:20];There is one additional, and very useful, feature of field isolation -- the field length can extend beyond the right end of the word. For example, this statement is perfectly legal and has a well-defined result:
X:= W.[7:16];With a starting bit of 7, there are only eight bits available on the right end of the word, so the field will wrap around to the high-order end of the word to obtain the remaining eight bits. When the field length wraps around like this, the original value is effectively rotated left until the low-order bit of the field is in the bit 0 position, then any bits above the starting bit (which has shifted to the left due to the rotate) are cleared to zero.
One application of this feature is the REPLACE statement. REPLACE is normally used to move characters from one pointer, string, or indexed-array expression to another, but it can also take an arithmetic expression as its source. The transfer always starts at bit 47 in the word for the arithmetic expression, with the bits in the word reused circularly until the FOR count of the statement is exhausted. Here is an example:
ARRAY A[0:89];
REAL W;
W:= 8"FOOBAR";
REPLACE POINTER(A[0],8) BY W FOR 90;This works fine if you are transferring at least a whole word's worth of bits, but if you have, say, a single byte right-justified in the value that you want to transfer, you need to rotate it to the high-order byte first, which you can do with the wraparound feature of field isolation, thus:
W:= 4"7F";
REPLACE POINTER(A[0],8) BY W.[7:48] FOR 1;Note that if you use a short literal string as the source, the Algol compiler rotates the literal for you. In the statement below, the compiler coerces 4"7F" to be 4"7F0000000000":
REPLACE POINTER(A[0],8) BY 4"7F" FOR 1;Finally, there are two Algol intrinsic functions that compute values from full-word arithmetic expressions, but are often useful when working with partial words. Both of these are implemented as E-mode instructions and are quite efficient.
ONEStakes a single arithmetic expression as an argument. It returns as its value the number of 1-bits in the expression. Thus,ONES(123)returns the value6.FIRSTONEalso takes a single arithmetic expression as an argument. It scans the bits in the expression from left to right, starting at bit 47, skipping over any leading zero bits, and returning the bit number of the first 1-bit, plus one. Thus, if bit 47 is set, it returns48; if bit 0 is the only one set, it returns1; if the word is zero, it returns zero.FIRSTONE(123)returns7.
Field Concatenation (Insertion)
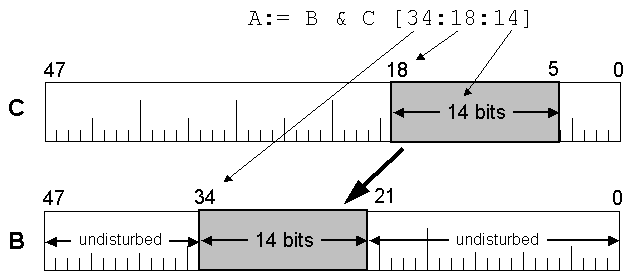
The opposite of partial-word field isolation is field concatenation, also known as field insertion. Instead of extracting a bit field from a value and returning the result right-justified over zeroes, this operation inserts a value into a bit field of an expression, leaving the other bits in the expression undisturbed. In Algol, this is another instance of arithmetic or Boolean expression, and has two forms:
B & C [dsb:ssb:nb]B & C [dsb:nb]
where B and C are arithmetic or Boolean expressions, and dsb, ssb, and nb are arithmetic expressions:
- dsb is the starting bit number in the destination expression value (
Bin this case) - ssb is the starting bit number in the source expression value (
Cin this case) - nb is the number of bits in the field to be transferred.
As with field isolation, the bit number and length expressions will be rounded to integers as necessary, the starting bit numbers must be in the range 0-47, and the length must be in the range 0-48.
The second form of expression is syntactic sugar for the common case where the source field is in the low-order bits of its value (C), i.e., where ssb = nb-1. Therefore this form is equivalent to:
B & C [dsb:nb-1:nb];
The second form is slightly more efficient than the first one, but the first is more general. It transfers the bit field [ssb:nb] from the source value into field [dsb:nb] of the destination value. Graphically, the operation works like this:
This operation is referred to as concatenation because the ampersand (&) expression can be repeated as many times as desired. This provides a convenient and efficient means to assemble a word from multiple partial-word fields. Thus, to assemble a single-precision, floating-point word from its component values using the second form of concatenation syntax:
W:= MANTISSA & EXPONENT[44:6] & EXPSIGN[45:1] &
MANTSIGN[46:1] & 0[47:1];Note that we are relying in this case on the fact that the mantissa occupies the low-order 39 bits of the word and that we are overwriting all the remaining bits with other concatenations. When assembling an entire word like this, it's often necessary to make sure that any bits you are not overwriting are zero. The most reliable way to do that is to start with a zero value and insert the fields explicitly into their locations, thus:
W:= 0 & MANTISSA[38:39] & EXPONENT[44:6] & EXPSIGN[45:1] &
MANTSIGN[46:1];We do not need to worry about zeroing [47:1] in this case because we know it will be zero. This operation could be written with the more general first form as follows:
W:= 0 & MANTISSA[38:38:39] & EXPONENT[44:5:6] & EXPSIGN[45:0:1] &
MANTSIGN[46:0:1];The ordering of the concatenation expressions is significant only if concatenated fields overlap. The field insertions are done in the order written, so insertions farther on the right may partially or completely overwrite the result of insertions farther on the left.
Partial-Word Assignment
Another operation, closely related to field concatenation/insertion, is partial-word assignment. In this case, the partial-word designator appears on the left side of an assignment:
W.[27:13]:= 25;Of course, the right-hand side can be any expression, so it is not unusual to see constructs like this:
W.[27:13]:= W.[27:13] + 1;This construct stores the value of the right-hand expression into the designated field of the variable on the left, leaving the rest of the bits in that word undisturbed. The variable on the left can be a scalar or an indexed array element.
One potential "gotcha" with partial-word assignment is the temptation to use it in an Algol multiple-assignment expression, thus:
X:= W.[27:13]:= 25;This type of construct has been flagged as invalid syntax for a long time, but before the compiler disallowed this usage, the result it produced was non-intuitive and confusing. I mention this because it illustrates how partial-word assignment is implemented -- it's simply syntactic sugar for assignment using a field concatenation expression. The assignment W.[27:14]:= 25 is actually implemented as this:
W:= * & 25[27:13];where the "*" indicates that the left-hand construct (just W in this case) is repeated at that position. Therefore, the assignment for X above (back when it was still legitimate) should be read as:
X:= W:= W & 25[27:13];Anyone who was expecting X to have a value of 25 would be disappointed, as I certainly was the first time I made this mistake many years ago. It was the value of the whole word resulting from the partial-word assignment, not just the value of the partial-word field, that was propagated to any assignment to its left. Assuming W initially had a value of zero, X would have been 25 × 2**15 = 819200. This makes sense when you see how it is implemented, but the non-intuitive result is no doubt the reason that multiple assignment to the left of a partial-word assignment is no longer valid syntax.
Bit Manipulation in COBOL
This post is mostly about bit manipulation in Algol, but it bears mentioning that a restricted version of the Algol partial-word capability is also available in COBOL-74 and -85. Both dialects support only field insertion, but you can use field insertion to accomplish field isolation quite easily.
Bit manipulation in COBOL is accomplished using a variant of the MOVE instruction:
MOVE source TO destination [ssb : dsb : nb]
where source and destination must be data items of USAGE BINARY or REAL. The items within the square brackets are all integer literals or arithmetic expressions and have the same meaning as for Algol field concatenation/insertion:
- ssb is the starting bit number in the source data item (0-47)
- dsb is the starting bit number in the destination data item (0-47)
- nb is the number of bits to be transferred (0-48)
Note, however, that ssb and dsb are reversed with respect to their positions in the Algol syntax. As in Algol, any bits outside of the [dsb:nb] field in destination are not affected by the move. For example:
77 W-SOURCE PIC S9(11) BINARY.
77 W-DEST PIC S9(11) BINARY.
MOVE W-SOURCE TO W-DEST [31:15:8].Aside from the reversed source and destination bit numbers, there are two things to note:
- Although COBOL
USAGE BINARYis essentially the same as Algol typeINTEGER, the compiler does not normalize the destination value to integer format before storing it when doing a partial-word move. Thus, shifting of the mantissa bits or integer overflow will not occur at the time the statement is executed, but if the destination field intersects with the exponent or sign fields, you could see unexpected behavior if the value is used arithmetically later. - Specifying literal starting bit numbers and lengths that cause field wraparound is flagged as a syntax error. Field wraparound can be achieved when the bit numbers and/or lengths must be evaluated at run time, however.
The equivalent of field isolation can be performed with this syntax by assuring that (a) the destination item is zero before the move and (b) specifying dsb = nb-1. The will cause the source field to be moved into the low-order bits of the destination word, e.g.,
MOVE ZERO TO W-DEST.
MOVE W-SOURCE TO W-DEST [31:15:16].Algol Coding Techniques
The Algol syntax for field isolation and concatenation/insertion is powerful and efficient, but you can get tired pretty quickly of typing all those brackets and colons. More importantly, the chance of mis-typing the bit numbers and lengths grows with the size of the program, as does the difficulty of spotting such errors. As always in software development, when the language does not provide the abstractions we need, we fall back on coding technique.
Using DEFINEs
The first thing you can do to ease the use of partial-word operations is to use the DEFINE declaration in Algol to hide the bracket syntax and literal bit numbers. There are a number of styles people use for this, but the one I prefer is to write defines for the individual fields. Using our earlier example of the layout of a floating-point word, a set of defines might look like this:
DEFINE
FLAGBITF = [47:1] #,
SIGNBITF = [46:1] #,
EXPSIGNF = [45:1] #,
EXPONENTF = [44:6] #,
MANTISSAF = [38:39] #;The "F" suffix to denote a field is a common convention in MCP source code. With these definitions, we can now refer to the fields in a word mnemonically, e.g.,
SIGNBIT:= W.SIGNBITF;
EXPONENT:= (IF BOOLEAN(W.EXPSIGNF) THEN -W.EXPONENTF
ELSE W.EXPONENTF);
W.SIGNBITF:= 0; % EQUIVALENT TO ABS(W)
W:= 0 & X MANTISSAF & E EXPONENTF;When writing field concatenations with mnemonic field designators, I prefer to put parentheses around the field values for readability, thus:
W:= 0 & (X)MANTISSAF & (E)EXPONENTF;To illustrate some techniques, the following are several defines I have found useful over the years. Note that some of the later defines make use of earlier ones:
BPW = 48 # % BITS PER WORDThe number of bits per word for MCP systems is not likely to change any time soon, but that number shows up frequently in partial-word expressions, so for clarity it is best to represent it mnemonically.
ALL1 = REAL(NOT FALSE) #This define efficiently creates a whole-word mask of 48 1-bits.
LOGICAL(A,OP,B) = REAL(BOOLEAN(A) OP BOOLEAN(B)) #This define is useful for doing full-word Boolean masking operations, hiding the necessary type transfers. It assumes that A and B are arithmetic expressions and OP is one of the Boolean masking operators, e.g., LOGICAL(A, AND, B).
XOR(A,B) = REAL(NOT BOOLEAN(LOGICAL(A, EQV, B))) #This shows how to generate exclusive-OR results in Algol.
CORRECTLY(V,N) = ((V).[(N)*8-1:BPW]) FOR (N) #This define handles the chore of rotating an arithmetic expression for a specified number of bytes so that it can be used as a source in a REPLACE statement, e.g., REPLACE P BY CORRECTLY(CRLF,2);
TESTBIT(BIT,V) = BOOLEAN((V).[(BIT):1]) #This define makes it convenient to test a bit in an arithmetic expression, e.g., IF TESTBIT(44, X-Y) THEN ...
MAKEBIT(BIT) = (0 & 1[(BIT):1]) #This creates a word value with the specified bit set and all other bits reset.
MAKEBIT2(B1,B2) = LOGICAL(MAKEBIT(B1), OR, MAKEBIT(B2)) #
MAKEBIT3(B1,B2,B3) = LOGICAL(MAKEBIT2(B1,B2), OR, MAKEBIT(B3)) #
MAKEBIT4(B1,B2,B3,B4)=LOGICAL(MAKEBIT2(B1,B2), OR, MAKEBIT2(B3,B4))#These defines create word values with any two, three, or four bits set, e.g., MAKEBIT3(15, 44, 32).
MAKEMASK(MASK) = (0 & (ALL1)MASK) #This define creates a word value with a string of all ones in the field designated by MASK, e.g., MAKEMASK([44:6]).
MASKFIRSTBIT(MASK) = (FIRSTONE(MAKEMASK(MASK)) - 1) #
MASKLENGTH(MASK) = (ONES(MAKEMASK(MASK)) #Sometimes you need to deconstruct a statically-defined field designator to determine its starting bit number and length in bits. These two defines do that.
Algol Data Structures
Standard Algol does not have facilities to define records or other aggregate data structures. Using word arrays and partial-word designators, however, you can define arbitrarily complex record and table structures with either fixed- or variable-length entries. With judicious use of defines, you can make these structures reasonably easy and reliable to manipulate. Defines also help document the structure and make it comprehensible to others. Using defines in this way has been common practice since the days of the B5500.
Partial-word operations allow you to pack multiple fields in a word and create highly space-efficient structures. This was an extremely important technique 30 or more years ago when memory was very expensive and available only in limited quantities. The partial-word operations, efficient as they are, do add processor overhead when inserting and extracting fields from tables, so there is a tradeoff between space efficiency and processor efficiency for packed structures. This trade off varies by application, but unless the tables are quite large, it may be better overall with our modern systems and large memories to forego some of the space efficiency and just store at least some fields in full words.
There seems to be two main schools of thought on how to write defines for table structures. The first uses an array identifier as a parameter and writes the defines to reference the word and field within the array. Using as an example the first two words of a disk file header structure, the defines might be written thus:
DEFINE
% WORD 0
MARKERF(HDR) = HDR[0].[47:16] #, %VALIDITY MARKER
BLOCKLENGTHF(HDR) = HDR[0].[31:11] #, % BLOCK LENGTH, WORDS
HDRLOCATIONF(HDR) = HDR[0].[20:21] #, % RECORD NUMBER
% WORD 1
OPENCOUNTF(HDR) = HDR[1].[47:12] #, % NR OF FILES USING HEADER
FILEKINDF(HDR) = HDR[1].[35:12] #, % FILEKIND ATTRIBUTE
PERMANENCYF(HDR) = HDR[1].[23:1] #, % 0=TEMPORARY, 1=PERMANENT
WRITTENONF(HDR) = HDR[1].[22:1] #, % FILE WRITTEN ON
WRITELASTROWF(HDR) = HDR[1].[21:1] #, % WRITTEN ON LAST ALLOC ROW
HEADERCHANGEDF(HDR) = HDR[1].[20:1] #, % HEADER DIRTY
HDRFIXEDSIZE(HDR) = HDR[1].[19:8] #, % SIZE OF FIXED PART, WORDS
HDRAVAILSPACEF(HDR) = HDR[1].[11:12] #, % WORDS AVAIL IN HEADERThis approach allows you to reference the fields in the header structure, thus:
LENGTH:= BLOCKLENGHTF(H);
OPENCOUNT(H):= OPENCOUNT(H)+1;
IF BOOLEAN(WRITTENONF(H)) THEN ...This technique could obviously be extended to support pointer expressions, vectors (e.g., the row address words in a disk file header), etc. The main disadvantage of this approach is that you are restricted to fixed offsets and a single entry within the array, unless you add a parameter to each define to supply a base offset for an entry.
The approach I use most often looks a little weird until you see how it is applied. With this approach, the fields above would be defined thus:
DEFINE
% WORD 0
MARKERF = 0].[47:16 #, % VALIDITY MARKER
BLOCKLENGTHF = 0].[31:11 #, % BLOCK LENGTH, WORDS
HDRLOCATIONF = 0].[20:21 #, % RECORD NUMBER
% WORD 1
OPENCOUNTF = 1].[47:12 #, % NR OF FILES USING HEADER
FILEKINDF = 1].[35:12 #, % FILEKIND ATTRIBUTE
PERMANENCYF = 1].[23:1 #, % 0=TEMPORARY, 1=PERMANENT
WRITTENONF = 1].[22:1 #, % FILE WRITTEN ON
WRITELASTROWF = 1].[21:1 #, % WRITTEN ON LAST ALLOC ROW
HEADERCHANGEDF = 1].[20:1 #, % HEADER DIRTY
HDRFIXEDSIZE = 1].[19:8 #, % SIZE OF FIXED PART, WORDS
HDRAVAILSPACEF = 1].[11:12 #, % WORDS AVAIL IN HEADERThe same references to the fields as above would be written as:
LENGTH:= H[BLOCKLENGHTF];
H[OPENCOUNT]:= H[OPENCOUNT]+1;
IF BOOLEAN(H[WRITTENONF]) THEN ...The advantage to this technique is that when you are packing multiple entries into one array row, it's easy to specify the offset to the beginning of the entry within the brackets, thus:
LENGTH:= H[BASE+BLOCKLENGHTF];
H[OPENCOUNT]:= H[BASE+OPENCOUNT]+1;
IF BOOLEAN(H[BASE+WRITTENONF]) THEN ...That is why I tend to prefer this second approach. There are further advantages and disadvantages in each approach, but often the choice simply comes down to personal preference.
Another application of the second approach is in accessing bits in a multi-word bit vector. In this case, we not only need to select a bit within a word, we also need to select the appropriate word within an array:
DEFINE BIT(X) = (X) DIV BPW].[(BPW-1) - (X) MOD BPW:1 #;Individual bits can then be accessed by a 0-relative index:
LENGTH:= VEC[BIT(BNR)];
VEC[BIT(BNR)]:= 1;
IF BOOLEAN(VEC[BIT(BNR)]) THEN ...I hope you have found this discussion of bit manipulation and partial-word operations in Algol useful and interesting. If anyone knows of additional applications or techniques in this area, please feel free to log comments to this post.
In the next post, I will return to MCP Express and additional topics for external networking.
Paul
Really enjoyed the blog!
As usual after reading your documentation or seeing one of your presentations, I am left annoyed. If only I had known this before spending hours (days) coming up with my own less than desirable solutions. 🙂
Another use for bit manipulation is a quick way of dividing an integer by a power of 2:
00000100 BEGIN
00000200%
00000220 DEFINE
00000240 DIV_2 (VAL) = VAL.[38:38] # , % Divide by 2
00000250 DIV_4 (VAL) = VAL.[38:37] # % Divide by 4
00000260 ;
00000300 INTEGER
00000400 IDX
00000500 ;
00000600 IDX := 10 ;
00000700 DISPLAY (STRING (IDX, *)) ; % Displays: 10
00000800 IDX := DIV_2 (IDX) ;
00000900 DISPLAY (STRING (IDX, *)) ; % Displays: 5
00001800 IDX := DIV_4 (IDX) ;
00001900 DISPLAY (STRING (IDX, *)) ; % Displays: 1
00002000%
90000000 END.
This technique was probably more useful years ago when machine clock speeds were much slower.
Curt
Thanks, Curt. I’ll agree that using partial-word field isolation to divide by powers of two probably has no significant benefit on modern systems. Since everything is emulated on Intel these days, it’s impossible to tell how the implementations of field isolate and integer divide would differ in timing.
Note that using field isolation to divide like this also produces the absolute value of the result, because it discards the sign bit. Also note that this is one instance where you REALLY need to be careful about the internal word format and how the numeric value may be normalized within the word. If it isn’t fully normalized as an integer, you’re screwed. In this case, since you are storing into an integer variable and then using the value from that variable directly, it should not be a problem.